Ternary Moral Logic and the Future of AI Governance
A comprehensive analysis of integrating TML into NVIDIA's ecosystem and the viability of triadic processor architecture

Strategic Imperative
NVIDIA's unique position to lead the AI governance revolution through TML integration
Executive Summary
This report provides a deep technical analysis of how Ternary Moral Logic (TML) can be integrated into NVIDIA's AI hardware and software ecosystem and evaluates the viability of a future triadic processor architecture. TML offers a paradigm for embedding ethical governance directly into AI systems through its eight foundational pillars, including the "Sacred Pause," "Moral Trace Logs," and "Hybrid Shield."
Core Conclusions
- • Immediate viability through NeMo Guardrails expansion
- • Software-first approach provides robust pathway to responsible AI
- • Triadic processor offers transformative long-term potential
- • Strategic advantage in regulated AI markets
Risk of Non-Adoption
- • Strategic obsolescence in maturing AI industry
- • Competitive disadvantage in regulated markets
- • Vulnerability to AI failures and misuse
- • Regulatory compliance challenges
The analysis concludes that NVIDIA can and should adopt TML, first as a software-based runtime governance architecture and, in the longer term, as a guiding principle for future hardware design. While technically challenging due to manufacturing and design constraints, a triadic processor offers a path to a more secure and tamper-proof ethical control layer.
TML as a Runtime Governance Architecture
The integration of Ternary Moral Logic (TML) into NVIDIA's existing AI ecosystem represents a paradigm shift from static, pre-deployment model alignment to a dynamic, runtime governance framework. This approach decouples governance logic from the model's internal cognition, treating it as a provisioned service that inspects and validates the model's observable inputs and outputs against declarative policies [33].
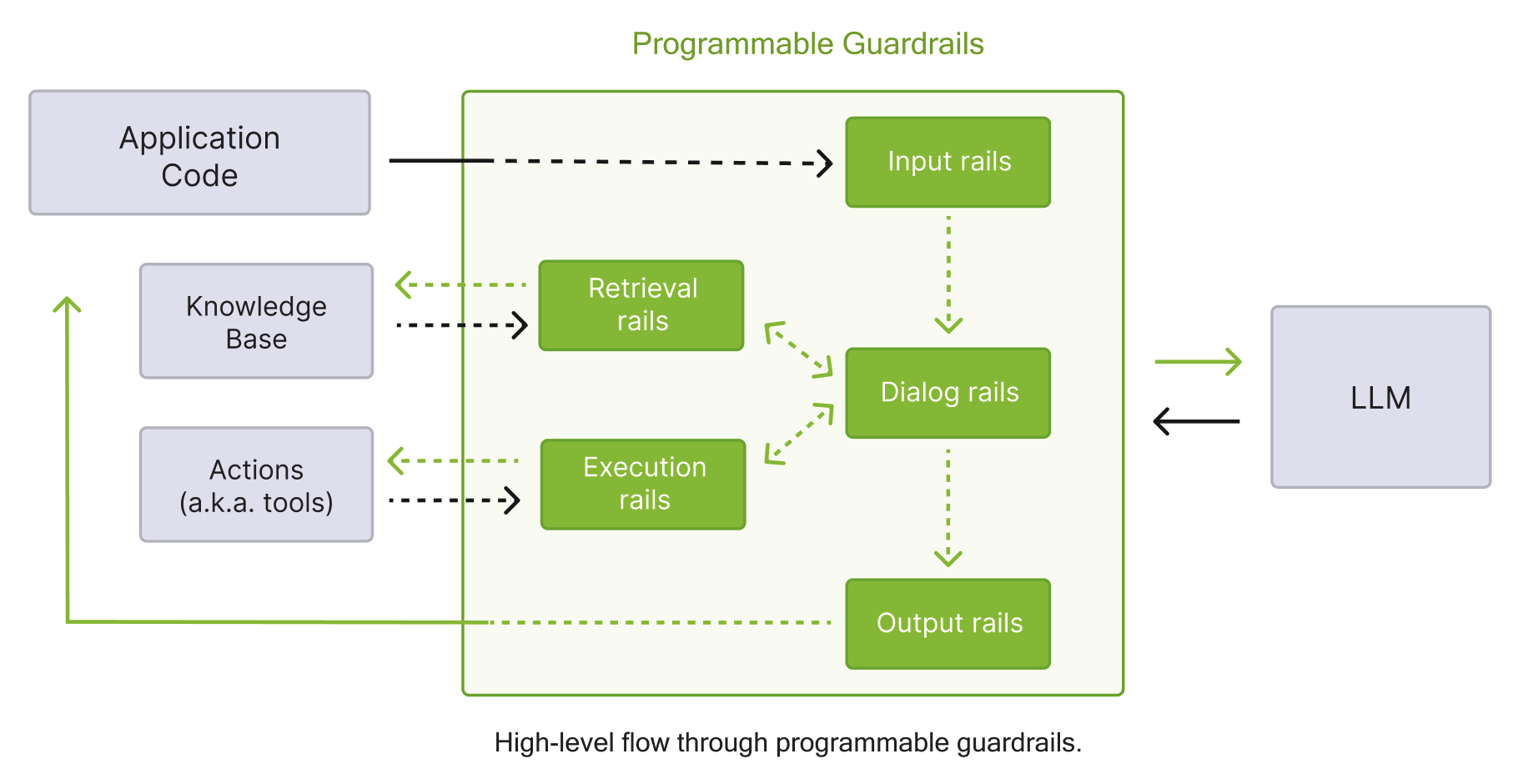
Integration Pathway via NeMo Guardrails
Input Rails
Proactive blocking of prompts containing known attack patterns, jailbreaking attempts, or prompt injection [139].
Output Rails
Reactive validation checking for policy violations, harmful content, sensitive information disclosure, or topic deviation [140].
Dialog Rails
Guiding conversational flow and maintaining context-aware governance through configurable policy logic [137].
Integration with Core NVIDIA Platforms
| Platform | Integration Strategy | TML Pillars Addressed | Technical Considerations |
|---|---|---|---|
| CUDA | JIT Compilation Hooks | Sacred Pause, Goukassian Promise, Moral Trace Logs | Injecting TML policy checks (PTX/LTO-IR modules) into the kernel at runtime via nvJitLink [180] |
| TensorRT | Pre-flight Governance Checks | Hybrid Shield, Human Rights Pillar | Challenging to interrupt mid-inference. Ethical checks must occur before engine execution or between partitioned model segments. |
| NeMo | Guardrails & Conditional Logic | Sacred Pause, Hybrid Shield, Moral Trace Logs | Most direct path. Use Colang to define ethical flows and pauses. Integrate with NIM microservices for safety models [107]. |
| Omniverse | Domain-Specific Governance | Earth Protection Pillar, Anchors | Govern digital twin creation and modification. Use blockchain anchors for asset provenance and collaborative integrity [88]. |
| Clara | Domain-Specific Governance | Human Rights Pillar, Sacred Pause | Enforce patient privacy, medical ethics, and diagnostic safety. "Sacred Pause" for low-confidence diagnoses. |
| DRIVE | Domain-Specific Governance | Human Rights Pillar, Sacred Pause | Critical for safety. "Sacred Pause" for ambiguous driving scenarios (e.g., unclassified obstacles), triggering safe-stop maneuvers. |
| Isaac (Robotics) | Domain-Specific Governance | Human Rights Pillar, Earth Protection Pillar | Ensure learned behaviors in simulation are safe before deployment. Log robot actions and sensor data using MCAP format [50]. |
Implementing the Eight TML Pillars in Software
| TML Pillar | Software Implementation Strategy | Key Technologies & Concepts |
|---|---|---|
| Sacred Pause | Conditional Execution Layer | NeMo Guardrails (Colang flows), JIT-compiled CUDA kernels with policy checks. |
| Always Memory | Persistent, Tamper-Proof Storage | High-performance DB (e.g., Kafka), IPFS for distributed storage, Merkle trees for integrity. |
| Moral Trace Logs | Structured, Forensic-Grade Audit Trail | MCAP format (from Isaac ROS), detailed logging of all governance actions and model I/O [50]. |
| Hybrid Shield | Multi-Layered Security & Ethics Framework | NeMo Guardrails (input/output/dialog rails), NVRx for fault tolerance, AccuKnox for runtime security [32] [34]. |
| Human Rights Pillar | Policy-Driven Constraints | Declarative policy files (e.g., JSON), policy engine evaluating actions against human rights rules. |
| Earth Protection Pillar | Policy-Driven Constraints | Declarative policy files, integration with carbon footprint data (e.g., NVIDIA PCF) for energy-aware scheduling [40]. |
| Anchors | Asynchronous Commitment to Public Blockchain | Oracles (e.g., Chainlink), IPFS for off-chain data storage, Merkle tree batching of log hashes [56] [58]. |
| Goukassian Promise | Formal Verification & Model Signing | OpenSSF Model Signing, sigstore PKI, runtime attestation of model signatures [101]. |
The Triadic Processor: A Forward-Looking Hardware Analysis
The concept of a triadic processor, inspired by the principles of Ternary Moral Logic (TML), represents a bold and speculative leap beyond the current binary paradigm of computing. Such a processor would be built around a three-state logic system, with the third state representing a "hesitation" or "undecided" condition. This hardware-level hesitation state would provide a physical embodiment of the "Sacred Pause" pillar of TML.
The Case for a Hardware-Level Hesitation State
Limitations of Software-Only Governance
- • Vulnerable to bugs and exploits
- • Potential for bypass or circumvention
- • Limited by binary processor architecture
- • Cannot provide fundamental tamper-proof protection
Hardware-Level Advantages
- • Fundamental, tamper-proof protection
- • Physical "Sacred Pause" instruction
- • Inherently resistant to unethical behavior
- • Higher assurance in critical situations
Electrical and Logical Feasibility
Tri-State Logic: Beyond Binary
Tri-state logic, or ternary logic, is the foundation of a triadic processor. Instead of the two states of binary logic (0 and 1), ternary logic uses three states, which can be represented as 0, 1, and 2, or more commonly as -1, 0, and +1 (balanced ternary).
The primary advantage is information density; a ternary system can represent more information with fewer components. For a given number of logic levels n, a ternary system can represent 3^n states, compared to 2^n for a binary system [147].
Novel Transistor Technologies
Carbon Nanotube FETs (CNFETs)
High-performance ternary logic gates demonstrated with low-dimensional materials [147].
Ferroelectric FETs (FeFETs)
Stable third state through ferroelectric material polarization.
Architectural Implementation Options
| Implementation Option | Description | Pros | Cons |
|---|---|---|---|
| Dedicated Governance Coprocessor | A separate chip or unit attached to a traditional binary CPU/GPU, handling all ethical and safety tasks. |
• Leverages existing binary technology
• Allows independent upgrade of governance logic • Isolates governance from main computation |
• Increased system complexity and cost
• Potential latency from inter-chip communication • May become a performance bottleneck |
| Triadic Execution Unit within GPU | A specialized execution unit inside a traditional GPU designed for ternary logic operations. |
• More gradual transition from binary
• Can accelerate specific tasks suited for ternary logic • Efficient use of existing GPU infrastructure |
• Complex integration with binary GPU architecture
• Requires new instruction sets and compilers • Limited to specific, non-general-purpose tasks |
| Future Full Ternary Core | An entire processor (CPU/GPU) built from the ground up on a ternary logic system. |
• Highest potential performance and efficiency
• Most robust and tamper-proof "Sacred Pause" • Enables novel computational paradigms |
• Requires a complete redesign of the processor and software stack
• Immense R&D and manufacturing investment • Very long development timeline |
Engineering Challenges and Constraints
Manufacturing Realities
Introduction of new materials like carbon nanotubes requires complete overhaul of established manufacturing pipeline [145]. Fabrication facilities optimized for silicon face monumental adaptation challenges.
Thermal & Power Constraints
Third intermediate voltage state may increase static power consumption and heat generation. Ternary logic gates must be highly optimized for energy efficiency to be viable alternatives.
Signal Integrity
Reduced noise margins make systems more susceptible to crosstalk and electrical noise [145]. Smaller voltage differences between three states require sophisticated error-correction techniques.
Patent & IP Implications
Complex landscape of patents for novel transistor designs, circuit layouts, and manufacturing processes requires thorough IP analysis and strategic patent portfolio development.
Performance, Privacy, and Storage Considerations
The integration of a comprehensive governance framework like Ternary Moral Logic (TML) into high-performance AI systems necessitates careful analysis of its impact on performance, privacy, and storage. While the ethical and safety benefits are clear, implementation must not unduly compromise the speed, efficiency, and scalability that are hallmarks of modern AI acceleration platforms.
Latency Analysis and the <2ms Dual-Lane Target
Performance Projections
| Component | Projected Latency | Notes |
|---|---|---|
| Hybrid Shield (Input/Output Rails) | < 1ms | Achieved through GPU acceleration and parallel execution of guardrails [106]. |
| Sacred Pause Controller | < 0.5ms | Requires highly optimized policy evaluation engine, potentially running on dedicated GPU. |
| Inference Pipeline Overhead | < 0.5ms | Minimal overhead from TML integration, assuming streaming architecture is used. |
| Total Dual-Lane Latency | < 2ms | Meets target latency for real-time applications. |
Privacy and Data Protection
GDPR-Safe Pseudonymization
To ensure compliance with data protection regulations like GDPR, TML implementation must incorporate robust pseudonymization mechanisms. Pseudonymization replaces identifying information with artificial identifiers, making data no longer attributable to specific individuals without additional information.
Implementation: Personally identifiable information (PII) in user input or AI output is replaced with pseudonyms (random identifiers or one-way hashes). Mapping between pseudonyms and original PII stored separately in secure, access-controlled database.
Encrypted Key Repository (EKR)
In addition to protecting user privacy, TML-governed systems must protect intellectual property and trade secrets of organizations developing and deploying AI models, including proprietary model architectures and training datasets.
Implementation: Secure, centralized system for managing cryptographic keys. Sensitive data within logs encrypted before storage, with encryption keys managed by EKR enforcing strict access control policies.
Storage and Anchoring Solutions
Merkle Tree Batching for Efficient Storage
The sheer volume of data generated by "Moral Trace Logs" makes it impractical to anchor every single log entry to a public blockchain individually. This would be prohibitively expensive and introduce unacceptable latency.
Batch Collection
Large number of log entries collected into batch
Merkle Tree
Constructed from hashes of log entries
Blockchain Anchor
Root hash anchored in single transaction
This approach significantly reduces blockchain transactions while providing efficient integrity verification. Any change to a single log entry would result in a different Merkle root, making tampering easily detectable.
Proposed Architecture Blueprint for TML Integration
High-Level System Overview
The proposed TML architecture consists of several key components working together to provide a comprehensive governance layer. The system is divided into three main layers: the Application Layer, the Governance Layer, and the Infrastructure Layer.
AI Models & Applications"] --> B["Governance Layer
TML Enforcement"] B --> C["Infrastructure Layer
Hardware & Storage"] B --> B1["Sacred Pause Controller"] B --> B2["Hybrid Shield"] B --> B3["Policy Engines"] B --> B4["Logging & Anchoring"] C --> C1["NVIDIA GPUs"] C --> C2["High-Performance Storage"] C --> C3["Blockchain Networks"] style A fill:#e3f2fd,stroke:#1976d2,stroke-width:2px,color:#0d47a1 style B fill:#f3e5f5,stroke:#7b1fa2,stroke-width:2px,color:#4a148c style C fill:#e8f5e8,stroke:#388e3c,stroke-width:2px,color:#1b5e20 style B1 fill:#fff3e0,stroke:#f57c00,stroke-width:2px,color:#e65100 style B2 fill:#fff3e0,stroke:#f57c00,stroke-width:2px,color:#e65100 style B3 fill:#fff3e0,stroke:#f57c00,stroke-width:2px,color:#e65100 style B4 fill:#fff3e0,stroke:#f57c00,stroke-width:2px,color:#e65100 style C1 fill:#fce4ec,stroke:#c2185b,stroke-width:2px,color:#880e4f style C2 fill:#fce4ec,stroke:#c2185b,stroke-width:2px,color:#880e4f style C3 fill:#fce4ec,stroke:#c2185b,stroke-width:2px,color:#880e4f
Application Layer
Where AI models and applications reside, such as LLMs running on NeMo, autonomous vehicle software on DRIVE, or robotics applications on Isaac. TML governance is applied externally without modifying core applications.
Governance Layer
Core of TML system consisting of microservices and libraries responsible for enforcing TML pillars: Sacred Pause Controller, Hybrid Shield, policy engines, and logging/anchoring services.
Infrastructure Layer
Underlying hardware and software infrastructure including NVIDIA GPUs for accelerating governance logic, high-performance storage for Moral Trace Logs, and blockchain networks for Anchors.
Core Component Design
Sacred Pause Controller
Central decision-making component responsible for evaluating ethical uncertainty of AI's proposed actions and triggering "Sacred Pause" when necessary. Implemented as high-performance, low-latency microservice.
Function: Takes proposed action, context, and ethical policies as input; outputs ternary decision: ALLOW, PAUSE, or BLOCK.
Always Memory Backbone
Persistent storage system for TML architecture responsible for storing all data needed to support TML pillars: Moral Trace Logs, policy configurations, and model signatures.
Implementation: Distributed, fault-tolerant database system combining Apache Kafka for real-time ingestion and time-series database like InfluxDB for long-term storage.
Moral Trace Log Layer
Responsible for generating and managing "Moral Trace Logs." Implemented as set of libraries integrated into NVIDIA ecosystem applications with simple API for logging events.
Features: Standardized schema formatting, timestamp metadata, cryptographic hashing for integrity, and digital signatures.
Hybrid Shield Implementation
Multi-layered security and ethics framework with NeMo Guardrails as central orchestration engine. Configures series of input, output, and dialog rails enforcing safety and ethical policies.
Capabilities: Highly modular design, GPU acceleration, parallel processing for minimal latency impact, complete audit trail logging.
Anchoring Pipeline
Responsible for committing "Moral Trace Logs" to public blockchain. Implemented as asynchronous worker processes running in background, independent of main inference pipeline.
Process: Periodically retrieves un-anchored logs, constructs Merkle tree from hashes, submits root to blockchain via smart contract, stores raw data on IPFS, updates database with transaction ID.
Phased Rollout and Implementation Plan
Software-Based Governance (0-12 months)
Focus on implementing TML pillars as software layer using NeMo Guardrails and existing NVIDIA tools. Goal: create functional, robust governance system deployable on current-generation hardware.
Deliverables: Sacred Pause Controller, Hybrid Shield implementation, Moral Trace Log Layer
Hardware Acceleration (12-24 months)
Focus on accelerating TML governance logic using NVIDIA GPUs. Optimize guardrail models for GPU execution and develop more efficient Sacred Pause Controller.
Goal: Achieve <2ms dual-lane latency target through GPU optimization and parallel processing
Triadic Processor Development (24+ months)
Focus on long-term goal of developing triadic processor. Significant R&D effort to overcome engineering challenges.
Vision: Hardware-level "Sacred Pause" providing robust, tamper-proof ethical governance
Comparative Analysis: NVIDIA vs. Other AI Hardware Vendors
NVIDIA is not the only company investing in AI hardware and software. A number of other vendors, including AMD, Intel, and Cerebras, are also developing their own AI platforms. This section provides a comparative analysis of how these vendors are approaching the challenges of AI governance and safety.
AMD
AI Governance Approach
AMD has been actively working on AI governance and trust through open-source software initiatives. Key contributor to OpenSSF (Open Source Security Foundation) developing tools for securing software supply chain, including Model Signing project [101].
Focus Area: Software-based security and open standards

Intel
Responsible AI Initiatives
Intel focuses on developing tools and frameworks helping developers build fair, transparent, and explainable AI systems. Leader in confidential computing using hardware-based Trusted Execution Environments (TEEs) to protect data and code in use.
Focus Area: Confidential computing and explainable AI

Cerebras
Wafer-Scale Engine Paradigm
Cerebras takes radically different approach with Wafer-Scale Engine (WSE) - single massive chip designed to accelerate training of large neural networks. Unique architecture features massive number of cores and high-bandwidth interconnect.
Focus Area: Performance and scalability (governance TBD)
NVIDIA's Competitive Advantage in Adopting TML
Strategic Differentiation
NVIDIA's adoption of TML provides significant competitive advantage by embedding comprehensive, verifiable ethical governance framework into platform, offering trust and safety levels unavailable from other vendors.
- • Key differentiator in regulated industries
- • Enterprise customers increasingly demand responsible AI
- • Hardware-based moat with triadic processor
Market Leadership
Combining AI performance leadership with pioneering approach to AI ethics creates truly unique and compelling value proposition for customers.
- • Future-proof against AI regulations
- • Deeper trust with developers and end-users
- • New markets where safety is non-negotiable